In this blog, we’ll talk about extracting a set of characters from the end of a text string based on the case of the text. This type of extraction will be useful while cleaning up your raw data for further analysis.
To understand this better, let us look at a sample data of department names that is extracted into Excel (as a table) from an external source.
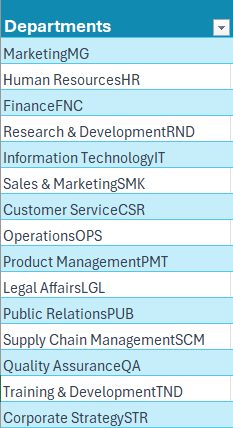
We can clearly see that the department names and the abbreviations are pulled together. To extract the abbreviations alone, follow the simple steps:
Step 01:
Firstly, let us extract the last three characters from the names in a new column using the RIGHT function in excel:
=RIGHT([@Departments],3)This gives us the last three characters:
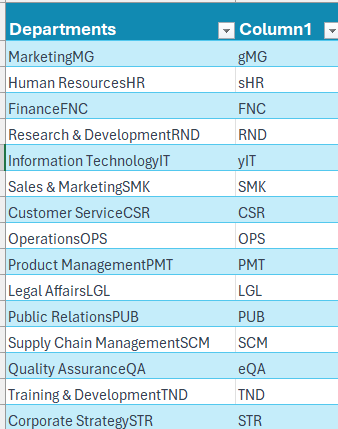
We can see that the extraction is not accurate as few departments have three-lettered abbreviations while few have only two.
Step 02:
How to extract the correct department abbreviation?
We’ll use the CODE function in Excel. This returns the code value for a text string.
This is case-sensitive and returns different values for lower and upper-case texts:
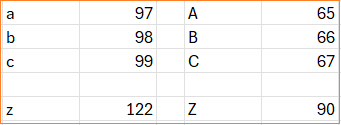
What can we observe from this set of values?
The upper case A-Z has a code value between 65-90.
Step 03:
With the information from the previous step, if we can identify only the upper case letters from the right, we can successfully extract the department abbreviations.
We’ll include another column with the following formula using a simple IF function and check the code value of the first string:
=IF(AND(CODE([@Column1])>=65,CODE([@Column1])<=90),[@Column1],RIGHT([@Column1],2))This function checks if the code lies between 65 to 90 and then returns the same abbreviation else remove the first character using the RIGHT function and return the two lettered abbreviation only.
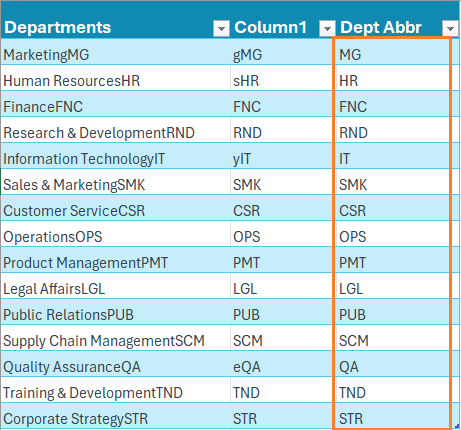
With the understanding of simple Excel functions like CODE, data cleanup for further manipulation and analysis is made easy!
Check our video on data cleanup on NFL games’ standings table here:
If you have any feedback or suggestions, please post them in the comments below.